Anthropic Now Has Three Separate Crawlers. Your Robots.txt Needs a Rethink
Key Takeaways:
Anthropic updated its crawler documentation to list three distinct bots: ClaudeBot, Claude-User, and Claude-SearchBot
Each bot has its own robots.txt user-agent string and its own blocking consequences
Blocking ClaudeBot stops AI training but does not block Claude from citing your content in search
The old "block all AI crawlers" approach no longer works as a one-size solution
OpenAI made a similar split in late 2024, and the pattern is becoming an industry standard
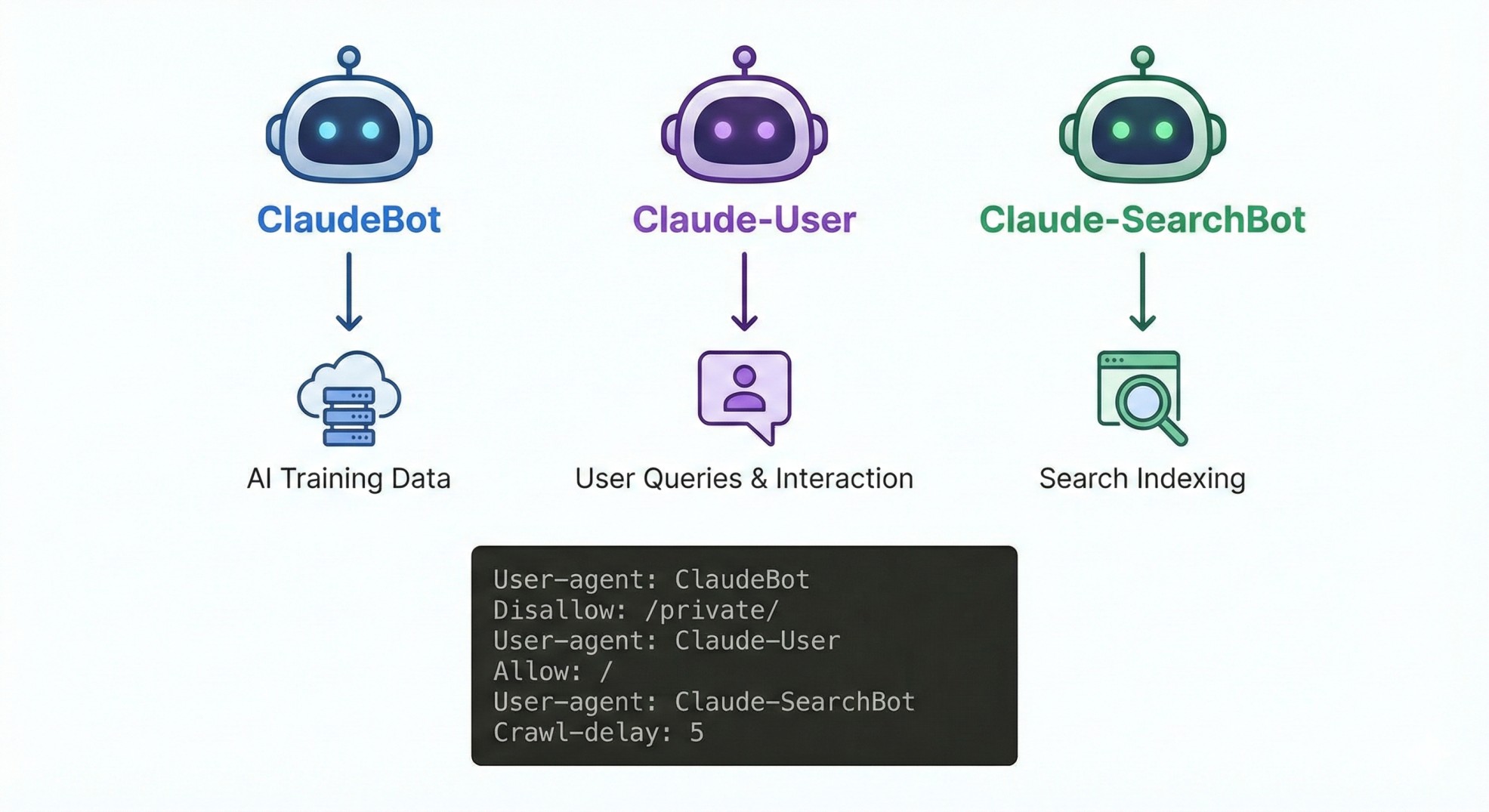
If you blocked ClaudeBot last year and thought you were done, you were wrong.
Anthropic updated its crawler documentation on February 20 with a formal breakdown of three separate web crawlers. Each serves a different purpose. Each has its own robots.txt user-agent. And blocking one does not block the others.
Three bots, three different jobs
ClaudeBot collects web content for AI model training. This is the one most publishers blocked in 2024. If you block it, Anthropic says your future content gets excluded from training datasets.
Claude-User fetches pages when someone asks Claude a question that requires accessing a website. This is the real-time browsing bot. Block it, and your site will not appear when Claude users ask questions.
Claude-SearchBot indexes content for search results. Blocking it means your pages may not surface in Claude-powered search. Anthropic warns this "may reduce your site's visibility and accuracy in user search results."
Each requires a separate robots.txt entry. If you want to block all three, you need three disallow rules. If you only want to block training while keeping search visibility, you block ClaudeBot and leave the other two alone.
Why this matters for your website right now
This mirrors what OpenAI did in late 2024 when it separated GPTBot, OAI-SearchBot, and ChatGPT-User. The industry is moving toward a model where every AI company runs multiple bots with different purposes.
The data backs up why this matters. Hostinger's analysis of 66.7 billion bot requests showed OpenAI's search crawler coverage grew from 4.7% to over 55% of sites sampled. Meanwhile, its training crawler coverage dropped from 84% to 12%. Publishers are actively choosing to allow search bots while blocking training bots.
The same logic now applies to Anthropic. You can protect your content from AI training while still appearing in AI-powered search results. But only if you update your robots.txt to handle each bot separately.
What publishers should do this week
The copy-paste blocklists that spread across SEO forums in 2024 need an audit. Here is what to check:
Open your robots.txt file
Look for any blanket disallow rules targeting ClaudeBot or anthropic-ai
Decide per bot: do you want to block training (ClaudeBot), user queries (Claude-User), search indexing (Claude-SearchBot), or some combination?
Add separate directives for each bot you want to block
Repeat this exercise for OpenAI's bots if you have not already
Anthropic also notes that IP-based blocking is unreliable because its crawlers run on public cloud providers. Robots.txt is the only dependable method.
AI search visibility is becoming a real traffic source. The decision to block or allow is no longer binary. It is three separate decisions, and each one carries different consequences.